快科技4月24日消息,今日,小米正式发布MiMo-V2.5语音模型,带来MiMo-V2.5-TTS系列与MiMo-V2.5-ASR。这是一套面向Agent时代的全链路语音模型系列,覆盖识别与合成两大核心能力,让语音的输入与输出都可以被语言自由调度。在语音合成方面,MiMo-V2.5-TTS系列提供三大模型,分别对应不同创作场景:
首先是MiMo-V2.5-TTS,内置多款高质量精品音色,经过专业调优,发音自然、情感贴合,并支持语速、情绪、语气等精细化控制,开箱即用,满足多场景表达。
小米MiMo-V2.5语音模型正式发布:一句话生成声音、克隆真人音色
其次是MiMo-V2.5-TTS-VoiceDesign,支持通过一句自然语言描述生成全新音色,无需任何参考音频。
用户可从年龄、性别、口音、音质乃至性格气质等多个维度自由定义,例如“低沉略带嘶哑的老年学者”或“元气满满的少女”,模型即可自动生成对应声音形象。
依托大规模预训练能力,模型对复杂、模糊、甚至相互矛盾的描述也能合理解读,而不局限于"男/女/青年/老年"这类粗粒度标签。
第三是MiMo-V2.5-TTS-VoiceClone,主打音色克隆能力,用户仅需提供数秒参考音频,无需训练或微调,即可复刻真人播客、配音演员、品牌代言人,或者用户本人声音。
复刻后的声音不仅保留了原始说话人的音色身份,也保留了气息、节奏、习惯性停顿等个人特征。
同时,克隆音色可继续叠加自然语言指令、音频标签、导演剧本级脚本,实现更高自由度的语音创作。
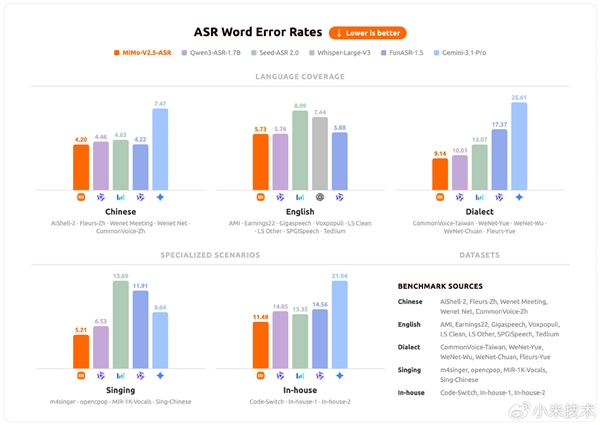
作为全链路语音模型系列的听觉基座,MiMo-V2.5-ASR在中英双语、中文方言、Code-Switch、强噪音、多说话人、高知识密度等复杂真实场景下均达到业界领先水平。
小米MiMo-V2.5语音模型正式发布:一句话生成声音、克隆真人音色
小米MiMo-V2.5语音模型正式发布:一句话生成声音、克隆真人音色
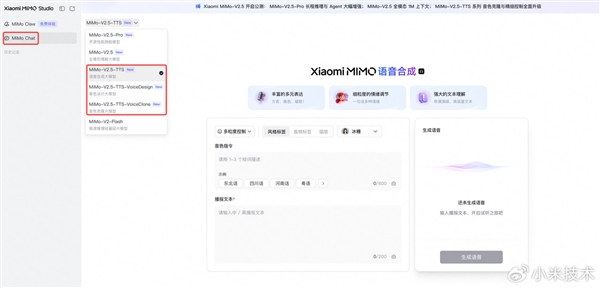
目前,MiMo-V2.5-TTS、MiMo-V2.5-TTS-VoiceDesign、MiMo-V2.5-TTS-VoiceClone已在Xiaomi MiMo API开放平台限时免费。

小米MiMo-V2.5语音模型正式发布:一句话生成声音、克隆真人音色
【本文结束】出处:快科技
- 本文固定链接: http://www.androidx86.cn/articles/67639.html
- 转载请注明: zhiyongz 于 安卓中文站 发表
《本文》有 0 条评论